摘要:制作个人聊天机器人笔记
1 聊天机器人简介
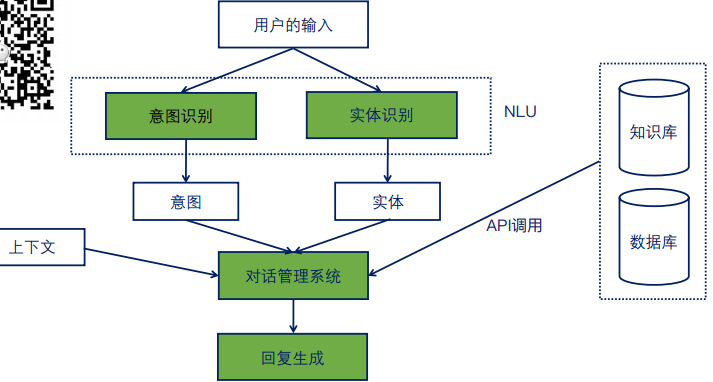
1.1 工作原理
1.1.1 核心模块
意图识别
分类器(SVM,深度学习)
实体识别
NER(命名实体识别)
对话管理系统
回复生成
1.2 关键技术
- 海量文本知识表示:网络文本资源获取、机器学习方法、大规模语义计算和推理、知识表示体系、知识库构建;
- 问句解析:中文分词、词性标注、实体标注、概念类别标注、句法分析、语义分析、逻辑结构标注、指代消解、关联关系标注、问句分类(简单问句还是复杂问句、实体型还是段落型还是篇章级问题)、答案类别确定;
- 答案生成与过滤:候选答案抽取、关系推演(并列关系还是递进关系还是因果关系)、吻合程度判断、噪声过滤
1.3 技术方法
- 基于检索的技术(淘汰)
- 基于模式匹配的技术(淘汰)
- 基于意图识别的⽅法
- ⽣成式⽅法(i.e.,端到端)
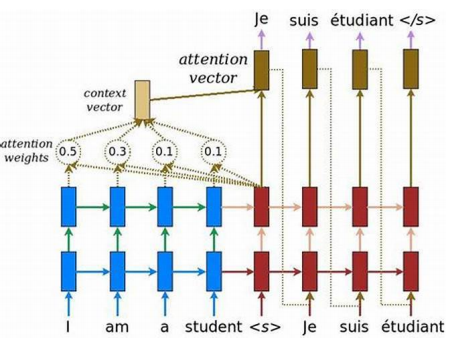
2 词性标注和关键词提取
2.1 安装
1 | pip install PyNLPIR |
2.2 初始化NLPIR
1 | import pynlpir |
2.3 分词及词性标注
1 | # 词性标注 pos_tagging=True;词性标注显示英文/中文 pos_english=True; 词性标记的显示方式 pos_names='parent/child/all' |
1 | s = 'NLPIR分词系统前身为2000年发布的ICTCLAS词法分析系统,从2009年开始,为了和以前工作进行大的区隔,并推广NLPIR自然语言处理与信息检索共享平台,调整命名为NLPIR分词系统。' |
如果不想词性标注,设置post_tagging为false:
1 | pynlpir.segment(s, pos_tagging=False) |
2.4 关键字提取
1 | # 获得多少个词:max_words=50; 显示关键字权重:weighted=True |
2.5 词性分类表
1 | POS_MAP = { |
3 通过爬虫获取语料信息
通过上节得到了关键词,想获取预料信息,通过几大搜索引擎的调用接口获取。
3.1 Anaconda安装Scrapy
首先查看anaconda中是否装有scrapy工具包,具体方法如下:
Anaconda Prompt / cmd命令中,输入 conda list,查看所有已经安装的工具包及版本号如果没有发现scrapy,则执行第2步。
输入 conda install -c scrapinghub scrapy ,等待片刻后,提示需要安装的相关工具包
proceed下输入y,回车, 自动进行安装相关的库。
再一次通过conda list 查看,就可以看到scrapy已经在list中了。安装成功。
3.2 创建Scrapy项目
打开Anaconda Prompt,切换到想要创建的目录下面
1
2
3
4
5cd D:\WorkSpace\Spider\
# 执行下面语句创建scrapy工程
scrapy startproject baidu_search
# 将会自动生成了baidu_search目录和下面的文件
创建baidu_search/baidu_search/spiders/baidu_search.py文件并对其进行配置,做好抓取器。进入baidu_search/baidu_search/ 目录下,执行
1
scrapy crawl baidu_search
4 依存句法和语义依存分析
4.1 依存句法分析
依存句法就是这些成分之间有一种依赖关系。什么是依赖:没有你的话,我存在就是个错误。“北京是中国的首都”,如果没有“首都”,那么“中国的”存在就是个错误,因为“北京是中国的”表达的完全是另外一个意思了。
4.2 语义依存分析
“语义”就是说句子的含义,“张三昨天告诉李四一个秘密”,那么语义包括:谁告诉李四秘密的?张三。张三告诉谁一个秘密?李四。张三什么时候告诉的?昨天。张三告诉李四什么?秘密。
4.3 语义依存和依存句法的区别
依存句法强调介词、助词等的划分作用,语义依存注重实词之间的逻辑关系。
另外,依存句法随着字面词语变化而不同,语义依存不同字面词语可以表达同一个意思,句法结构不同的句子语义关系可能相同。
4.4 依存句法分析和语义依存分析对聊天机器人有什么意义呢?
依存句法分析和语义分析相结合使用,对对方说的话进行依存句法和语义分析后,一方面可以让计算机理解句子的含义,从而匹配到最合适的回答,另外如果有已经存在的依存句法、语义分析结果,还可以通过置信度匹配来实现聊天回答。
4.5 依存句法分析到底是怎么分析的呢?
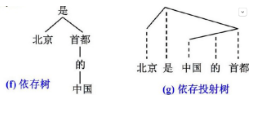
依存句法分析的基本任务是确定句式的句法结构(短语结构)或句子中词汇之间的依存关系。依存句法分析最重要的两棵树:
依存树:子节点依存于父节点
依存投射树:实线表示依存联结关系,位置低的成分依存于位置高的成分,虚线为投射线
4.6 依存关系的五条公理
- 一个句子中只有一个成分是独立的
- 其他成分直接依存于某一成分
- 任何一个成分都不能依存于两个或两个以上的成分
- 如果A成分直接依存于B成分,而C成分在句子中位于A和B之间,那么C或者直接依存于B,或者直接依存于A和B之间的某一成分
中心成分左右两面的其他成分相互不发生关系
什么地方存在依存关系呢?比如合成词(如:国内)、短语(如:英雄联盟)很多地方都是
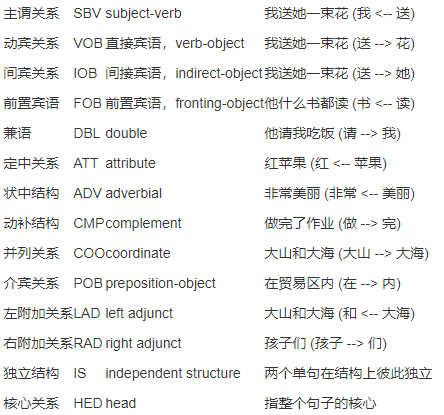
4.7 LTP依存关系标记
4.8 那么依存关系是怎么计算出来的呢?
是通过机器学习和人工标注来完成的,机器学习依赖人工标注,那么都哪些需要我们做人工标注呢?分词词性、依存树库、语义角色都需要做人工标注,有了这写人工标注之后,就可以做机器学习来分析新的句子的依存句法了
4.9 LTP云平台怎么用?
首先注册用户,得到每月免费20G的流量,在http://www.ltp-cloud.com/注册一个账号,注册好后登陆并进入你的dashboard:http://www.ltp-cloud.com/dashboard/在dashboard里还可以查询自己流量使用情况。具体使用方法如下(参考http://www.ltp-cloud.com/document):
5 语言模型
业界目前比较认可而且有效的语言模型是n元语法模型(n-gram model),它本质上是马尔可夫模型,简单来描述就是:一句话中下一个词的出现和最近n个词有关(包括它自身)。详细解释一下:
如果这里的n=1时,那么最新一个词只和它自己有关,也就是它是独立的,和前面的词没关系,这叫做一元文法
如果这里的n=2时,那么最新一个词和它前面一个词有关,比如前面的词是“我”,那么最新的这个词是“是”的概率比较高,这叫做二元文法,也叫作一阶马尔科夫链
依次类推,工程上n=3用的是最多的,因为n越大约束信息越多,n越小可靠性更高
n元语法模型实际上是一个概率模型,也就是出现一个词的概率是多少,或者一个句子长这个样子的概率是多少。
这就又回到了之前文章里提到的自然语言处理研究的两大方向:基于规则、基于统计。n元语法模型显然是基于统计的方向。
5.1 语言模型的应用
这几乎就是自然语言处理的应用了,有:中文分词、机器翻译、拼写纠错、语音识别、音子转换、自动文摘、问答系统、OCR等